
Model Resuability in SparkML Library
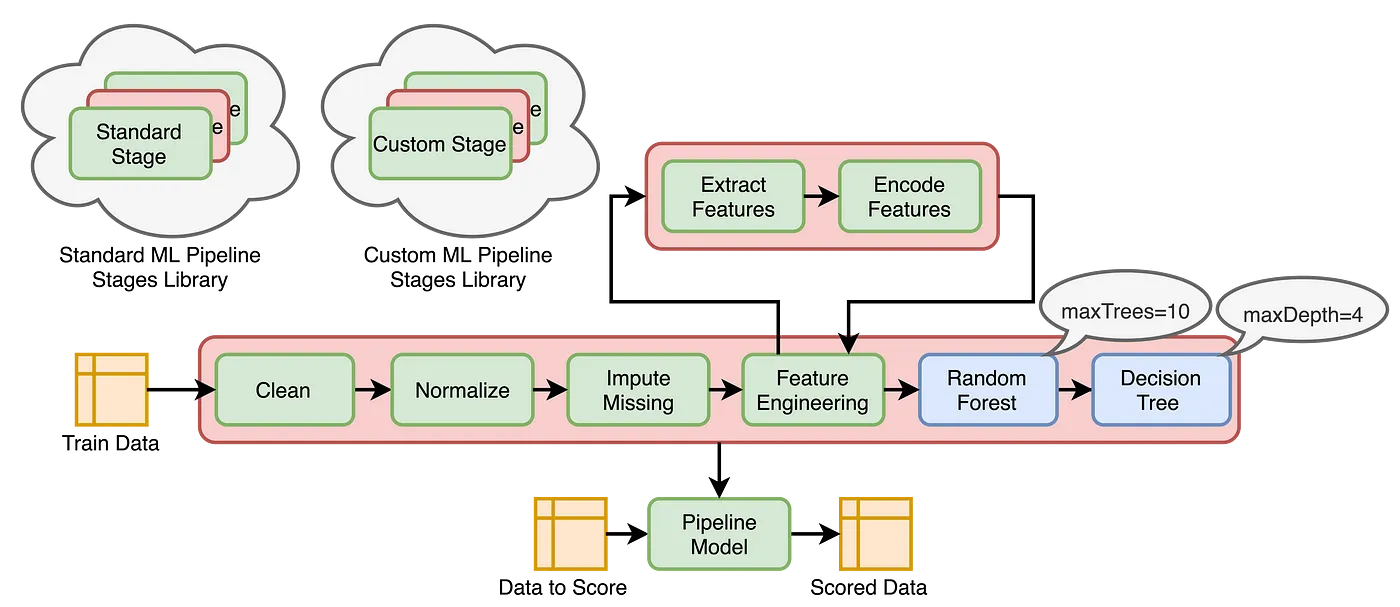
This project demonstrates the development and integration of custom estimators and transformers within the SparkML pipeline framework.
Using a loan prediction dataset, I perform exploratory data analysis to understand the raw data. The preprocessing steps include:
- Converting feature data types using custom estimators and transformers
- Imputing missing values with custom estimators and transformers
- Indexing categorical feature levels using StringIndexer
- Encoding categorical features using OneHotEncoder
- Assembling input features into a vector using VectorAssembler
I then built a logistic regression model and interpreted the results. A pipeline was created, encompassing all preprocessing stages and model building steps. The final PipelineModel was used to save the model artifact, which I then successfully reloaded to score new/unseen data without retraining.
This project showcases the flexibility of SparkML, the power of custom components, and the efficiency of model reusability in machine learning workflows.